십수 년간 데이터 다루는 일을 해왔는데, 정작 머릿속에 남은 게 아무것도 없이 느껴졌다. 그래서 시작했던 것이 빅데이터에 대한 학습이다. 이 글의 목적은 (1) 빅데이터 분석가나 데이터 사이언티스트에 대해 관심 있는 이들에게 정보를 제공하는 것과 (2) 개인적인 학습 내용을 정리해보고 기억해두기 위한 목적으로 작성됐다.
(대상) 이 글은 데이터 사이언스를 전문적으로 공부한 이들에게 햇병아리 수준의 콘텐츠가 될 수도 있겠다. 하지만 아직 빅데이터에 문외한인 사람이라면 앞으로 이어갈 이 카테고리의 포스팅을 차례차례 학습 해갈 경우 빅데이터의 개념적 이해를 넘어서 전문적인 통계 기법이나 빅데이터 모델링까지 손쉽게 진도를 개척해나갈 수 있는 도구가 될 것이다.
(TODAY) 학습할 내용은 빅데이터의 개념과 정의, 빅데이터가 전통적인 관계형 DB와 다른 어떤 특징을 가지고 있는지에 대해 살펴본다. 진부한 내용은 스킵하고 핵심이라고 여길 만한 것들만 요약해본다.
<목차>
1. 빅데이터의 뜻, 개념 정의
2. 빅데이터의 특징, 5V
3. 데이터의 유형과 소스
1. 빅데이터(Big Data)의 뜻, 개념 정의
이렇게 이해하고 있는 사람을 많이 봤다. "빅데이터는 세상의 떠돌아다니는 온갖 정보를 담고 있는 대용량 데이터 혹은 저장 창고이다."라고. 하지만 이것은 하나만 알고 둘은 모르는 것이다.
Wikipedia에서는 다음과 같이 정의하고 있다. "빅데이터는 기존 데이터베이스 관리 도구의 능력을 넘어서는 대량의 정형 또는 비정형 데이터(텍스트 등) 집합까지 포함한 데이터로부터 가치를 추출하고 결과를 분석하는 기술이다."
즉, 빅데이터는 단순히 대량의 데이터 저장소를 의미하는 것이 아니라, 다양한 종류의 데이터로부터 가치를 추출하고 결과를 분석하는 '기술'을 의미한다.
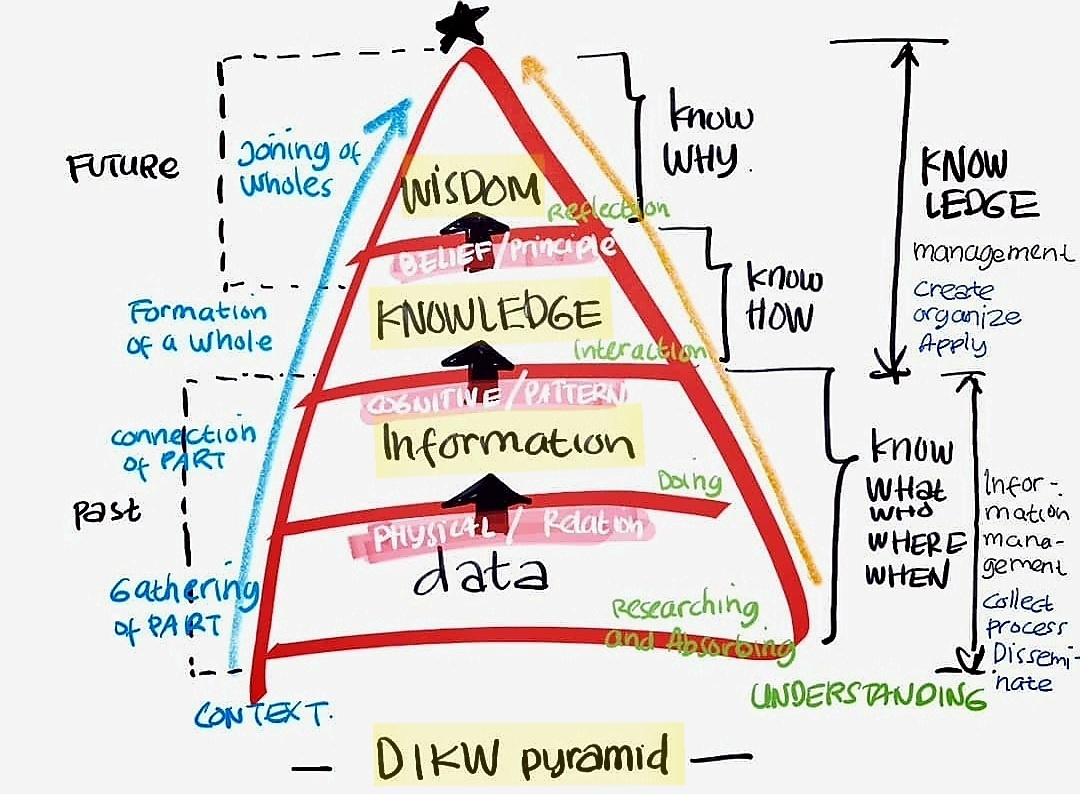
이는 어찌 보면 정보시스템이나 지식 관리 영역에서 흔히 사용되는 DIKW 피라미드를 상기시킨다. 여기서 DIKW란 '(D) Data-데이터, (I) Information-정보, (K) Knowledge-지식, (W) Wisdom-지혜'를 나타낸다. 단순히 데이터나 인포메이션을 넘어서 지식과 지혜를 추출해내는 기술이 빅데이터인 것이다.
2. 빅데이터의 특징
빅데이터의 특징을 설명할 때 자주 나오는 약어가 있다. 바로 '3V' 혹은 '5V'이다. 각각이 의미하는 것이 무엇인지 짤막하게 짚어본다. 사실 이건 그냥 단어의 조합이다.
3V는 세 개의 V, 즉 Volume, Variety, Velocity를 가리킨다.
빅데이터는 가장 먼저, 데이터의 양적인 측면인 볼륨(Volume)의 증가와 밀접하게 연관되어 있다. 알다시피 IT 기술과 서비스가 발전하고 일상화되면서 디지털 정보량이 기존 데이터 수집 및 관리/처리 소프트웨어의 수용 한계를 넘어설 만큼 증가하고 있다.
둘째, 데이터의 종류와 유형이 다양성(Variety)을 띠는 방향으로 진화하고 있다. 과거의 데이터의 대부분이 정형 데이터(주소, 이름, 나이 등)였다면, 현재의 데이터는 비정형 데이터(오디오, 비디오, SNS 대화, 상품평 등)의 차지하는 비중이 훨씬 더 크다.
셋째, 데이터의 양적인 증가와 내용의 다양성 때문에 대규모 데이터의 빠른 처리속도(Velocity)와 분석 속도가 요구된다.
여기까지 세 가지 빅데이터의 특징을 조합한 것이 3V인데, 여기에 다른 특징들을 조합해서 5V로 표현하기도 한다.
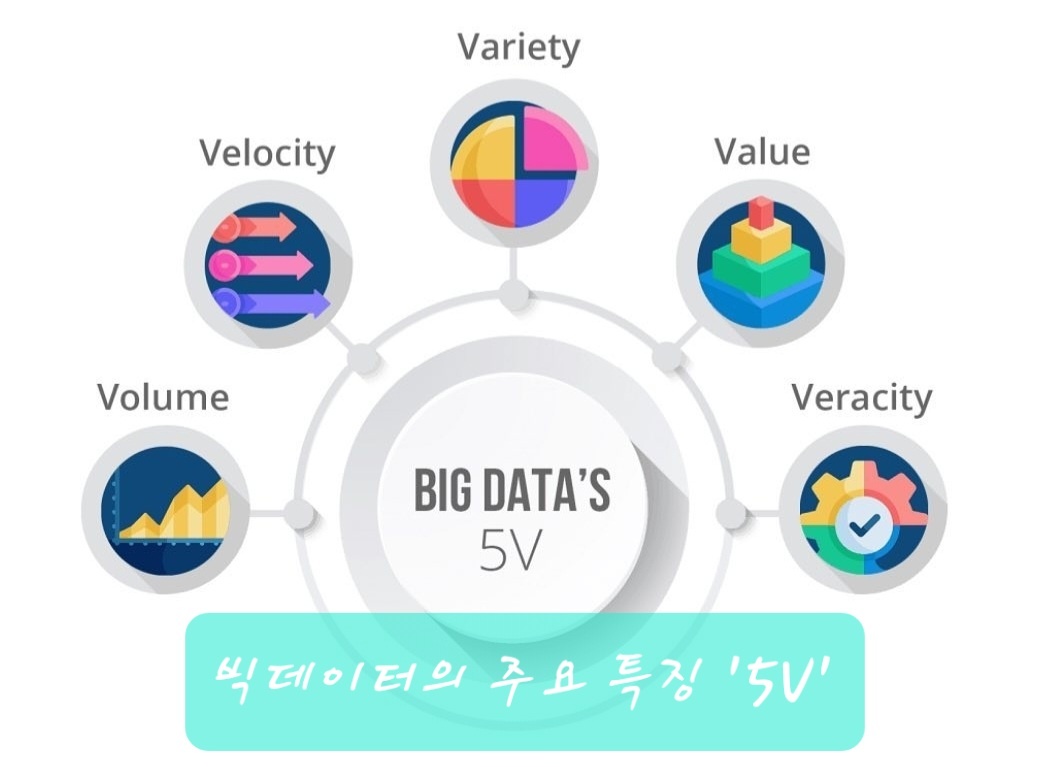
3V(Volume, Variety, Velocity)에 Value(가치), Veracity(정확성)를 더해서 5V로 표현한다. 여기서 '가치(Value)'란 빅데이터 기술의 핵심이라고 할 수 있다. 기존 DBMS(Database Management System)이나 데이터 분석 시스템으로 처리하기 어려운 대용량 데이터에 함축된 가치를 찾는 것이 바로 빅데이터 기술의 핵심인 것이다. 다른 한 가지 정확성(Veracity)은 빅데이터가 요구되는 또 하나의 속성이다. 데이터의 정확성, 타당성, 신뢰성은 데이터를 통한 의사결정이 무엇보다 중요해진 현재의 비즈니스 환경에서 빼놓을 수 없는 데이터의 속성이기 때문이다.
5V에 두 가지 V를 더해서 7V라고 지칭하기도 한다. 여기서 추가되는 두 가지 V는 유효성(Validity)와 휘발성(Volatility)이다.
3. 데이터의 유형과 소스
앞서, 정형 데이터와 비정형 데이터에 대해 언급했는데, 간략히 이에 대한 의미를 살펴본다. 데이터의 유형을 크게 다음 세 가지로 분류한다. (1) 정형 데이터, (2) 반정형 데이터, (3) 비정형 데이터까지 세 가지로 분류하는데, 빅데이터는 이 모든 데이터 유형을 포괄하는 데이터 크기와 데이터 복잡도를 가진다고 이해하면 좋겠다.
아래 이미지에 설명되어 있는 것처럼, 정형 데이터(Structured Data)는 행(rows), 열(columns) 구조가 일반적인 관계형 데이터베이스 등 유형으로, 숫자/날짜/문자열(strings) 등이 대표적인 예이다. Gartner에서 추정하기로는 기업 데이터의 20%가 정형 데이터 속성을 보인다고 한다. 정형 데이터는 많은 용량의 저장공간을 필요로 하지 않으며, 관리와 보안에 용이하다.
정형 데이터의 대표적인 데이터 소스로는 거래 데이터, 로그 데이터, 시계열 데이터, DB to DB, Sqoop, EAI(Enterprise Application Integration), ETL(Extract, Transform, Load) 등을 통한 수집 데이터 등이 있다.
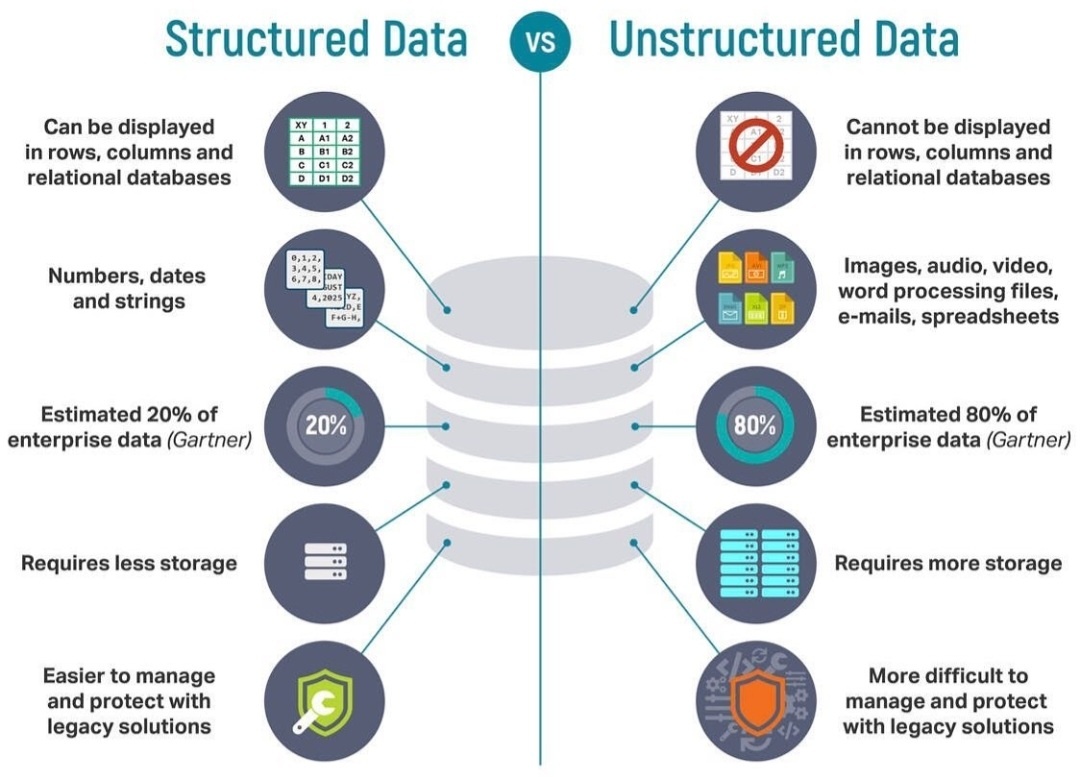
이에 비해 비정형 데이터(Unstructured Data)는 행이나 열, 관계형 데이터베이스로 표현될 수 없는 이미지, 오디오, 비디오, 워드 프로세싱 파일, 이메일, 스프레드 시트 등의 것을 의미한다. 센서 데이터라고 부르는 온도, QR 코드, RFID, GPS 등도 이 비정형 데이터에 속한다. 비정형 데이터는 큰 저장공간을 요구하며, 정형 데이터와 달리 관리와 보안에 난도가 높다.
반정형 데이터(Semi-structured Data)라는 데이터 유형도 있다. 이는 정형 구조의 데이터 모델을 준수하지 않는 정형 데이터의 한 형태로서, 데이터 내부에 있는 메타 데이터라고 보면 된다. HTML, XML, JSON, RSS, 웹로그 등이 반정형 데이터의 데이터 소스이다. 가령 어떤 이미지가 있는데, 겉으로 보이지는 않지만 이 이미지 안에 숨어있는 이미지의 속성 값, 즉 이미지 생성일, 시간, 일자, 장소 등이 메타 데이터의 한 예이다.
종합해서 정리하면 이와 같은 정형 데이터, 반정형 데이터, 비정형 데이터 등 다양한 유형과 대량으로 발생하고 있는 데이터의 수집부터 저장, 처리, 관리에 이르는 데이터의 새로운 접근 방법(혹은 기술)을 빅데이터라고 이해할 수 있다. <끝>
'BIG DATA' 카테고리의 다른 글
| 변수(Variable) 독립변수 종속변수 매개변수 외생변수 조절변수 억압변수 통제변수 내생변수 (1) | 2022.06.19 |
|---|---|
| 빅데이터 정제의 개념, 처리 방식, 주요 솔루션 (1) | 2022.06.18 |
| 데이터 측정 척도 종류 (명목·서열·등간·비율 척도) (1) | 2022.06.10 |
| 데이터 유형별 데이터 수집 기술의 종류 (2) | 2022.06.06 |
| 데이터 사이언티스트에게 필요한 기술과 능력 (+데이터 마이닝, 머신러닝, 딥러닝 개념) (1) | 2022.06.04 |




댓글